The massive parallelism of GPUs provides ample of performance for certain algorithms in scientific computing. At the same time, however, Amdahl's Law imposes limits on possible performance gains from parallelization. Thus, let us look in this blog post on how *few* threads one can launch on GPUs while still getting good performance (here: memory bandwidth).
An often important aspect is the cost of thread synchronization. Compute units in GPUs are arranged in so-called Streaming Multiprocessors (NVIDIA terminology) or Stream Units (AMD terminology), within which threads can be synchronized relatively easily and exchange data through fast, on-chip shared memory. Synchronization across {Streaming Multiprocessors|Stream Units} is usually achieved on the kernel level and is thus fairly expensive.
Performance optimization guides from both AMD and NVIDIA recommend to use 'many' logical threads when programming in OpenCL or the NVIDIA-only CUDA. Suggested values are beyond 10,000 threads overall. On the other hand, each thread block (CUDA terminology) or workgroup (OpenCL terminology) can consist of at most 1024 threads (newer NVIDIA GPUs) or 256 threads (AMD GPUs).
Ideally, I want to have fast synchronization across all threads. With the thread limits per {thread blocks|workgroups} stated above, I cannot run enough threads in a single {thread blocks|workgroups} to saturate the hardware well. So the next-best compromise is to run as few {thread blocks|workgroups} as possible, for example in the first step of a reduction operation. This was the trigger for writing short benchmarks for the memory bandwidth obtained for vector addition in dependence of the thread configuration. CUDA and OpenCL result in the same performance, but feel free to verify yourself by rerunning the benchmarks.
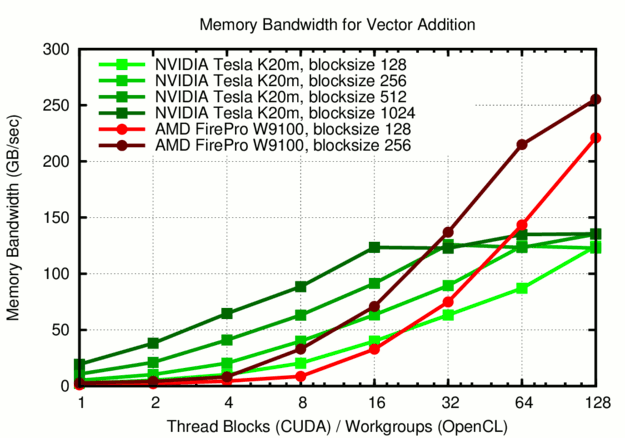
Comparison of the effective memory bandwidth obtained for different thread block sizes (CUDA) or workgroup sizes (OpenCL). The NVIDIA GPU is able to provide 90 GB/sec with only 8 thread blocks, while AMD GPUs require at least 20 workgroups to reach the same bandwidth.
The results are interesting for multiple reasons. Most importantly, the NVIDIA Tesla K20m are able to provide most of their peak memory bandwidth for only 8 {thread blocks|workgroups} with 1024 logical threads each. The AMD FirePro W9100 achieves only a third of the bandwidth of the NVIDIA GPU at 8 {thread blocks|workgroups}, requiring about 32 {thread blocks|workgroups} to get close to peak performance. At 128 workgroups the memory bandwidth on the AMD GPU is finally saturating, reflecting the higher number of hardware compute units in AMD GPUs as compared to NVIDIA GPUs. At this configuration, however, the W9100 provides substantially better bandwidth than the K20m. Another interesting observation is that the obtained bandwidth below saturation is primarily determined by the total number of threads: On the K20 one obtains almost exactly the same bandwidth for e.g. 4 thread blocks with 1024 threads each, 8 thread blocks with 512 threads each, 16 thread blocks with 256 threads each, and 32 thread blocks with 128 threads each. The W9100 provides the same bandwidth for e.g. 16 workgroups with 256 threads each and 32 workgroups with 128 threads each. Thus, 4096 threads provide almost exactly the same memory bandwidth on both devices! With the smaller upper limit on the threads per workgroup one is, however, a little less flexible on the W9100.
Overall, this simple benchmark yet again confirms my observations of AMD GPUs often providing the better peak performance than NVIDIA GPUs, but that peak is harder to reach. In a follow-up post I will discuss an actual algorithm where good performance for small workgroup sizes becomes important. Stay tuned!
This blog post is for calendar week 3 of my weekly blogging series for 2016.