The June 2016 update of the Top500 brought a new leader: The Sunway TaihuLight at the National Supercomputing Center in Wuxi, China. Given that Tianhe-2 has been leading the Top500 since three years, a new leader was overdue. Let us have a closer look at a couple of interesting details of Sunway TaihuLight.
One Master, Many Workers, Small Caches
Each node of the TaihuLight consists of four core groups, connected by a network on chip. A core group consists of a master core (dual pipeline, user and system mode) orchestrating 64 workers (single pipeline, user mode only). All cores run at 1.45 GHz and can process 8 floating point operations per cycle per core. There does not seem to be any dynamic clock frequency adjustment implemented; after all, these cores are supposed to run at full load all the time anyway.
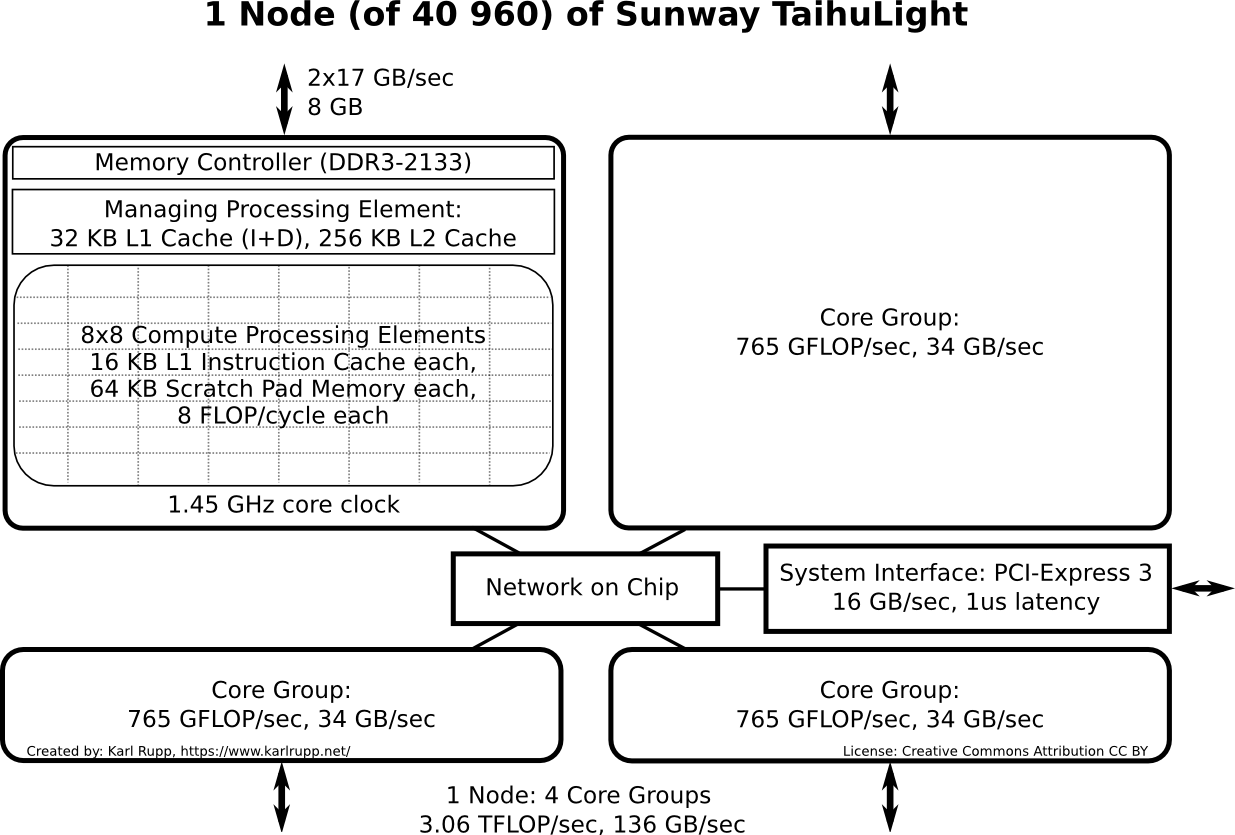
Node Schematic of Sunway TaihuLight. Each node consists of four core groups, each contributing 765 GFLOP/sec of processing power and 34 GB/sec memory bandwidth.[.svg]
Each worker core runs a single thread (no hyperthreading) and provides 11.6 GFLOP/sec of processing power. The master core contributes 23.2 GFLOP/sec (two pipelines, only one for worker cores). All cores feature 256-bit vector instructions such that each register can hold 8 double-precision floating point numbers (note: As of June 21, 2016, the report by Jack Dongarra on Sunway TaihuLight mentions 264-bit vector instructions; I assume this to be a typo). In contrast to mainline HPC processors from Intel, large caches are absent in the Sunway TaihuLight. Only the master core has a 256 KB L2 cache, whereas the worker cores have no data cache at all. Instead, each worker core is equipped with 64 KB of scratchpad memory. Thus, worker cores are actually fairly GPU-like, particularly when considering the vector with of 8 double-precision floating point units (NVIDIA GPUs currently have a warp size of 32, but NVIDIA's Path to Exascale paper speculates that a warp size of 8 is a better fit).
Arithmetic Intensity
Each core group provides a compute capability of 3.06 TFLOP/sec at a memory bandwidth of 136 GB/sec. This amounts to 22.5 floating operations per byte, which is well beyond the FLOP-per-byte ratio of competing devices: Current Xeon CPUs show a FLOP-per-Byte ratio of about 10, Intel's latest Xeon Phi (Knight's Landing) has a FLOP-per-byte ratio of about 8 with MCDRAM (about 26 for data in DDR4-SDRAM), and the NVIDIA Tesla P100 shows a FLOP-per-byte ratio of 10. Still, the Sunway TaihuLight CPUs just follow the trend of increasing FLOP-per-byte ratios over the years. The remarks about the relatively low memory per node (32 GB) on Sunway TaihuLight in Dongarra's report about Sunway TaihuLight need to be taken with a pinch of salt: MCDRAM on the new Xeon Phi (KNL) is merely 16 GB. If your application runs out of MCDRAM, you will be facing a FLOP-per-byte ratio on KNL that is higher than for Sunway TaihuLight. In this regard, Sunway TaihuLight is more 'honest' in the sense that sudden performance drops beyond a certain problem size are not part of the hardware design. In other words: Why is there DDR4-RAM on KNL after all?
Why do I care about arithmetic intensity? If you are running bandwidth-intense applications, such as almost anything that has to do with solving partial differential equations, memory bandwidth is your primary metric. This is also reflected in new HPC benchmarks such as HPCG, which evaluates a scalable conjugate gradient solver preconditioned by geometric multigrid. On supercomputers today, HPCG is (unfortunately?) just a more complicated way of running the STREAM benchmark. Sunway TaihuLight offers 136 GB/sec theoretical peak memory bandwidth per node, which results in about 5.5 PB/sec overall. In comparison, each of the 16000 nodes of Tianhe-2 provides about 700 GB/sec of memory bandwidth, resulting in an overall memory bandwidth of 11 PB/sec. This difference of a factor of two is largely replicated in the latest HPCG performance results: 0.58 PFLOP/sec for Tianhe-2, 0.37 PFLOP/sec for Sunway TaihuLight. Thus, Sunway TaihuLight is without a doubt a great machine towards Exascale according to the LINPACK metric, but it may be a step back in terms of average application performance where memory bandwidth matters.
No ccNUMA
Each of the four core groups has its own memory space. If I understand this correctly, this means that there is no cache-coherent non-uniform memory access (ccNUMA). This also implies that you can't run OpenMP programs beyond a single core group. In terms of memory locality, this is a very sensible decision, since one typically uses MPI across nodes anyway. Thus, Sunway TaihuLight enforces a programming model with high data locality. If there is one thing that US supercomputers could learn from Sunway TaihuLight, I vote for this: "Get rid of threading across NUMA domains".
The Embargo Strikes Back
The US embargo regulations restricting the sale of US processor technology pushed back China's HPC timeline. With Sunway TaihuLight in production, one has to question the embargo decision: Sure, it delayed China's plans for a year or two, but it also encouraged them to channel their money into their own microprocessors. Instead of making money from China's rise in HPC, USA decided to not take the money. But it couldn't stop China from taking the lead in terms of the total number of supercomputers in the Top500; plus, they now achieved it with their own technology. On the other hand, I wonder whether these Chinese CPUs will ever be available in Europe...
Conclusions
Sunway TaihuLight is a well-engineered machine for FLOP-intensive workloads such as LINPACK. The absence of expensive ccNUMA, the homogeneous memory system (unlike GPU-based supercomputers), and the fact that it is the result of a government-sponsored activity make it a very interesting machine that is likely to influence future supercomputers. On the other hand, the price tag of about 270 million USD for the building, hardware, R&D, and software is considerable. Time will tell if the machine was worth the investment from the perspective of science-per-dollar. Maybe this is not a question in China, but it certainly is for supercomputers built from public funding in Europe.
Resources
- SVG of Sunway TaihuLight node architecture schematic
- Report on the Sunway TaihuLight System (Jack Dongarra)
- China Debuts 93-Petaflops ‘Sunway’ with Homegrown Processors (HPCwire)
- Intel’s next-generation Xeon Phi, Knights Landing, now shipping to developers (ExtremeTech)
- NVIDIA Debuts PCIe-based P100; Broadens Aim at CPU Dominance (HPCwire)
This blog post is for calendar week 14 of my weekly blogging series for 2016.