While the number of floating point operations per second (FLOPs) is often considered to be the primary indicator for achievable performance, in many important application areas the limiting factor nowadays is memory bandwidth (cf. memory wall). The standard benchmark to measure memory bandwidth is the STREAM benchmark. Despite its simplicity of 'just simple vector operations', the benchmark is a very helpful indicator for actual application performance. For example, in an SC'14 paper on optimizations of the HPCG benchmark on the Xeon Phi the STREAM benchmark is repeatedly taken as a reference. The net bandwidth for HPCG as reported in the paper is about 65 to 80 percent of the STREAM benchmark, so the STREAM benchmark is also a good indicator for the performance of HPCG. (One may argue whether just using the much simpler STREAM benchmark instead of HPCG is a more productive way of benchmarking supercomputers...)
For FLOP-limited applications one can estimate the actual performance on X cores by multiplying the performance on a single core with X. For applications limited by memory bandwidth, such a linear extrapolation is usually wrong on CPUs, because a few cores may already saturate the memory channels. Results I obtained for the last three Xeon-generations (in dual socket configurations) as well as the Xeon Phi are as follows:
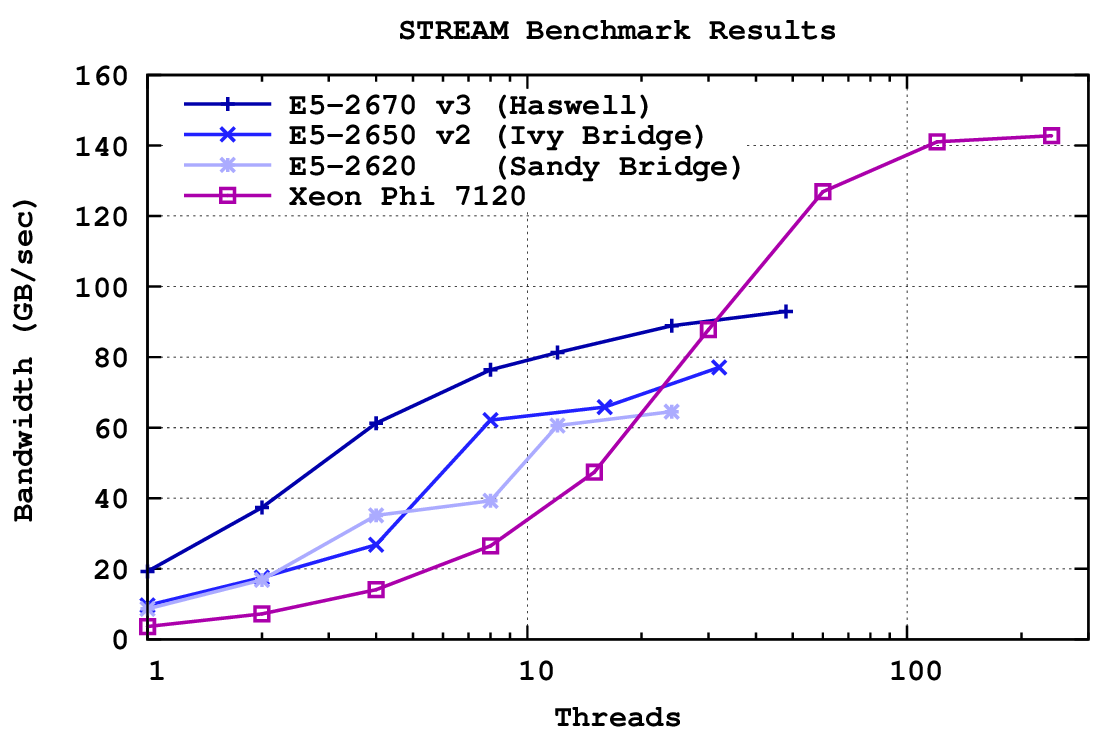
STREAM triad benchmark results for the latest three Intel Xeon generations (dual socket) and the Xeon Phi. While the Xeon Phi offers superior memory bandwidth at high thread counts, the achievable memory bandwidth is considerably higher on Xeon CPUs when using less than 30 threads.
The Intel Compiler (2013 and 2015 editions) was launched with
-O3 -openmp -DSTREAM_ARRAY_SIZE=64000000
for the Xeon CPUs and with
-mmic -O3 -openmp -DSTREAM_ARRAY_SIZE=64000000
for the Xeon Phi. Even though Intel recommends a few additional flags for tuning the STREAM benchmark, I consider such a microtuning of optimization flags as impractical for software libraries and applications.
What can we learn from these results? First and foremost, for any memory-bound application using less than about 30 threads, Xeon CPUs are the better choice. Also, on Xeon CPUs one obtains about 15 to 25 percent of peak STREAM bandwidth using a single core, while on the Xeon Phi one only obtains 2.5 percent. In other words, the memory bandwidth for a single core on the Xeon Phi is by up to a factor of ten smaller than on the Xeon CPUs. Thus, if you predict a parallel speedup using Amdahl's Law, keep in mind that the sequential paths in your program will take longer to execute on a Xeon Phi as compared to a Xeon CPU.
The question which originally led me to this benchmark comparison can now also be answered: How many threads (or processes) are required to obtain about 80 percent of the available peak memory bandwidth? For the Xeon CPUs this is the case with about 10 threads, resulting in a four-fold performance gain over a single core. On the Xeon Phi 60 threads are required to get reasonably close to peak performance, with a fairly sharp drop for lower thread counts.
Additional Resources
Download STREAM benchmark raw data