Intel Edison is a tiny computer (smaller in size than a credit card) targeted at the Internet of Things. Its CPU consists of two Silvermont Atom-CPUs running at 500 MHz and is offered for a price tag of around 70 US dollars. Even though Intel Edison is not designed for high performance computing, the design goal of low power consumption makes it nevertheless interesting to look at from a high performance computing perspective. Let us have a closer look.
In the following I will look at Intel Edison in terms of floating point operations per second (GFLOPs) and in terms of memory bandwidth. Although these two metrics do not provide a full picture of the requirements of a scientific computing cluster, they serve as a first-order approximation. The first is the only metric used for the TOP500 supercomputers, the latter is currently the limiting factor for High Performance Conjugate Gradients (HPCG). Here I will use the simpler and more productive approach for measuring memory bandwidth by means of the STREAM benchmark. As always, raw results are available for download.
Matrix-Matrix Products on Intel Edison
Results for matrix-matrix products were obtained using OpenBLAS 0.2.15 with target 'ATOM':
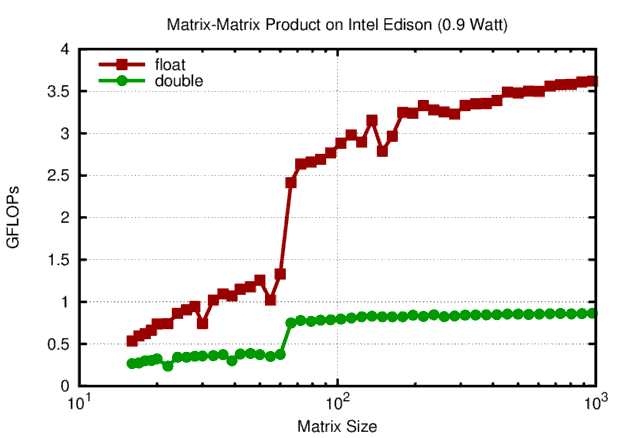
Raw floating point performance of the Intel Edison for matrix-matrix products using OpenBLAS.
At slightly below 1 Watt of power consumption, the Intel Edison achieves close to 4 GFLOPS in single precision and 1 GFLOPs in double precision. It is interesting to observe a factor of four difference here, because usually a factor of two is observed for conventional x86 CPUs. The reason for this difference is not clear to me: Maybe it is a hardware limitation, maybe it has to do with the implementation used by OpenBLAS. Either way, current supercomputers achieve about 2 GFLOPs per Watt in double precision. Even if we subtract an idle power consumption of 0.4 Watt of the Intel Edison, it is still not more energy efficient than current supercomputers.
What could be done to further improve GFLOPS/Watt on the Intel Edison? Add a few vector registers and vector instructions (AVX, AVX2, etc.), increase clock frequency a little, maybe add a few more cores. Oh, this is actually what Intel did for the Xeon Phi (Knights Landing, KNL)! KNL packs 72 such cores supplemented with AVX512 (2 vector units per core) and enables 4 threads per core.
STREAM Benchmark Results on Intel Edison
STREAM benchmark results for memory bandwidth are as follows:
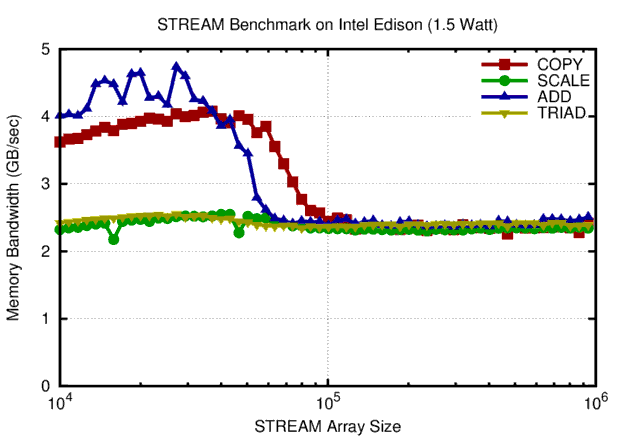
STREAM benchmark results on Intel Edison. A peak bandwidth of 2.5 GB/sec is obtained for large arrays. This is about one quarter of the peak bandwidth of DDR3 SDRAM.
The Intel Edison achieves a peak memory bandwidth of 2.5 GB/sec for large array sizes (thus not running in cache). This is about a quarter of what a standard DDR3-SDRAM channel is able to provide. For comparison: On my laptop equipped with an Core i3-3217U CPU I obtain a memory bandwidth of 9 GB/sec with 15 Watts of power consumption. A proper dual-channel configuration might double memory bandwidth to 18 GB/sec without increasing power consumption considerably.
The power consumption of 1.5 Watt for STREAM is significantly higher than the 0.9 Watt for matrix-matrix products. This adds an interesting new perspective: Data transfer from and to main memory is more expensive in terms of power consumption than raw computing power. Maybe Intel could reduce overall power consumption further by integrating memory on the same chip. This, again, allows for an analogy with KNL, which provides on-chip high bandwidth memory.
Conclusion
The lower clock frequency and the design goal of small power consumption of the Intel Edison does not lead to high energy efficiency for scientific computing purposes: The 2 GFLOPs/sec in single precision of the Intel Edison are below the power efficiency of current supercomputers. Similarly, a memory bandwidth of 2.5 GB/sec at 1.5 Watt is not a lot better than the memory bandwidth provided by laptops in dual channel configuration. This indicates (and clearly is not a proof) that current HPC hardware is already very power efficient. Let us have a look into the future given these numbers: Achieving exascale at a power budget of 20 Megawatt is tough, as this implies 50 GFLOPs/Watt. Just a factor of 25 from what we have today. As the Intel Edison shows, reducing clock frequencies (and thus ramp up parallelism) won't suffice.
This blog post is for calendar week 8 of my weekly blogging series for 2016.