My popular blog post on CPU, GPU and MIC Hardware Characteristics over Time has just received a major update, taking INTEL's Knights Landing and NVIDIA's Pascal architecture into account. Moreover, I added a comparison of FLOPs per clock cycle, which I want to discuss in slightly greater depth in this blog post.
When talking about parallelism, one frequently talks about the number of cores. 22 CPU cores in a high-end Xeon CPU sound like a lot, but are few compared to the thousands of processing units in a GPU. Relating each of these GPU processing units with a CPU core is, however, inappropriate: GPU multiprocessors operate batches of their processing units in a lock-step manner, so divergent code paths cannot be processed independently. NVIDIA calls these batches 'warps', whereas AMD calls them 'wave fronts'. Such batch-operation is, however, not specific to GPUs: With the introduction of AVX in CPUs, in particular AVX2 with many masked operations, one can achieve very similar execution behavior than on GPUs. Writing the necessary code with intrinsics is not straight-forward, but in some cases a compiler may be able to do the transformation for you. Therefore, this similarity of a 'thread' in a warp or wave front and an operand in a CPU vector register suggests to identify the two: Both can contribute one fused multiply-add operation per clock cycle. Thus, a direct comparison of parallel capabilities in CPUs and GPUs is obtained when looking at FLOPs per clock cycle, here for double precision arithmetic:
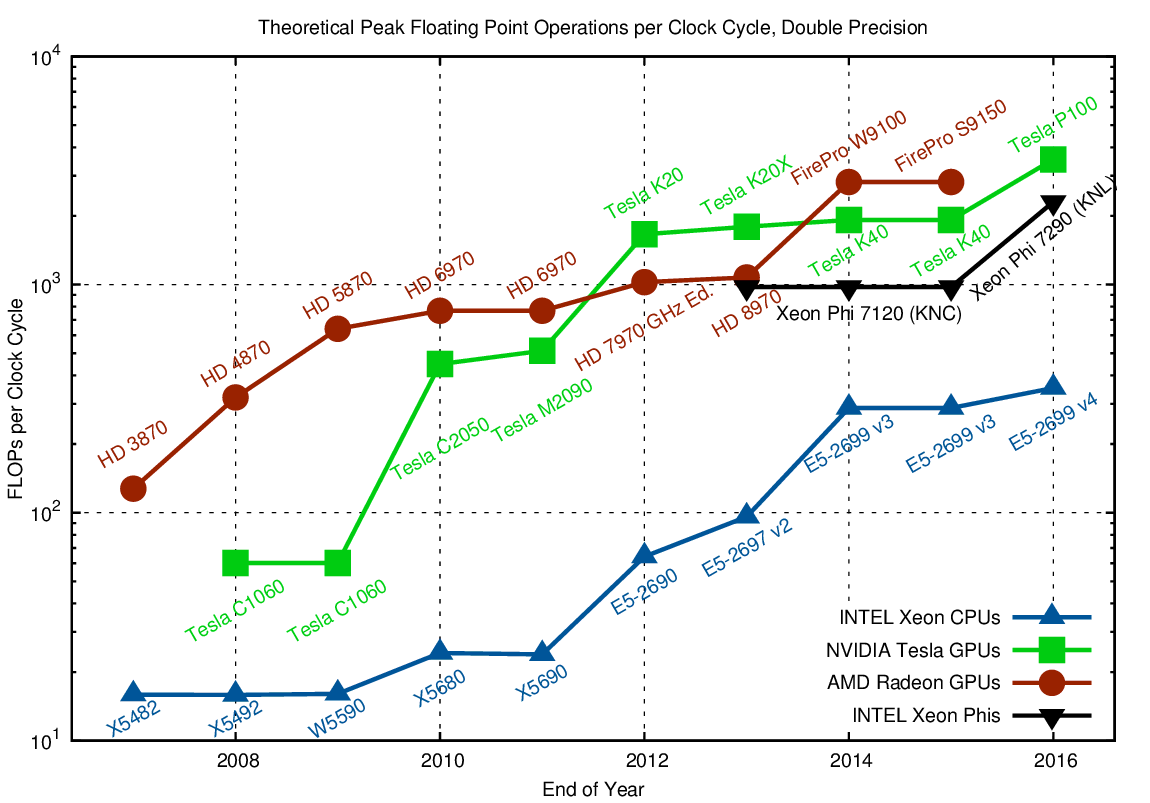
The number of FLOPs per clock cycle (unity for a purely sequential CPU) is in the tens for CPUs and in the hundreds for GPUs and Xeon Phi. Only parallelization and vectorization can leverage the full potential.
For comparison: A single-core CPU with no vector units is able to provide only one (two in the case of fused multiply-add) FLOP per cycle. Thus, if you write sequential code with poor data layout and no vectorization opportunities, you only leverage a few percent of your compute resources - even on CPUs.
Comparing the data for GPUs and CPUs one finds that CPUs today offer as many FLOPs per cycle as GPUs in 2009 - but CPUs today have far higher clock speeds than GPUs in 2009. The upcoming Skylake Xeon CPUs are likely to increase the FLOPs per cycle by another factor of two. This will not only make Xeon CPUs even more similar to Xeon Phis, but will also reduce the gap to GPUs further.
Conclusions
From the hardware perspective it is getting harder to fuel CPU-vs-GPU discussions/flamewars; the compute architectures are getting more and more similar. In particular, I find it breath-taking to see more than 300 FLOPs per clock cycle in double precision on today's high-end CPUs. If only the memory bus were fast enough to supply all the operands from main memory...
This blog post is for calendar week 16 of my weekly blogging series for 2016.