The Knights Landing (KNL) update of Intel's Xeon Phi product line is now available. For the applications I'm primarily interested in, namely the numerical solution of partial differential equation, the typical bottleneck is memory bandwidth. To assess memory bandwidth, the STREAM benchmark is the de-facto standard, so let us have a look at how KNL compares to the previous Xeon Phi generation (Knights Corner, KNC) as well as to the Xeon product line.
KNL promises superior memory bandwidth thanks to integrated multi-channel DRAM (MCDRAM) with a bandwidth up to 500 GB/sec. Since the capacity of MCDRAM is only 16 GB, KNL also includes six DDR4 memory channels. They provide only about 100 GB/sec of bandwidth, but a capacity of up to 384 GB. For further details on the architecture, I refer to the various tech sites who provide a detailed overview of KNL, e.g. [KNL on tom's hardware] [KNL on The Next Platform]
An important question from the algorithmic point of view is the memory bandwidth obtained if only few cores are busy. Ideally, a single core can fully saturate the memory channels. My earlier comparison of STREAM benchmark results for Xeon Phi KNC and Xeon CPUs showed, that a single core achieves only a small fraction of peak memory bandwidth, particularly on KNC. This made it very hard to achieve good performance on KNC, because stages with low parallelism led to a more significant slow-down than fully parallel sections were accelerated.
Dealing with MCDRAM
There are three ways of using MCDRAM from an application point of view: Either as transparent last-level cache, as a separately addressable memory ("flat mode"), or as a combination of the former. Flat mode offers the best performance for applications, but requires changes to the code (memory allocation) or the execution environment (NUMA node). The latter is typically controlled via numactl, since MCDRAM is exposed as a separate NUMA node in flat mode.
For the purposes of running STREAM, all we need to do is to compile the benchmark via
$> icc stream.c -O3 -o stream -fopenmp -DSTREAM_ARRAY_SIZE=64000000
(more sophisticated, but infrequently used optimization flags are described here) and then run with
numactl --membind 0 ./stream # DDR4
numactl --membind 1 ./stream # MCDRAM
This setup uses 64 million entries in each vector, allowing for a direct comparison with my earlier comparison of STREAM benchmark results for Xeon Phi KNC and Xeon CPUs.
Extracting the respective bandwidth from the benchmark output requires a bit of bash trickery; feel free to look up the code in the KNL benchmark repository supplementing this blog post.
Results
KNL finally delivers what KNC was by many expected to deliver. The memory bandwidth per KNL core is about 11 GB/sec for small thread counts, while KNC only provided 3.6 GB/sec. Thus, KNL is comparable in performance to Sandy Bridge and Ivy Bridge Xeon CPUs when running only a few threads. This is good news for many applications.
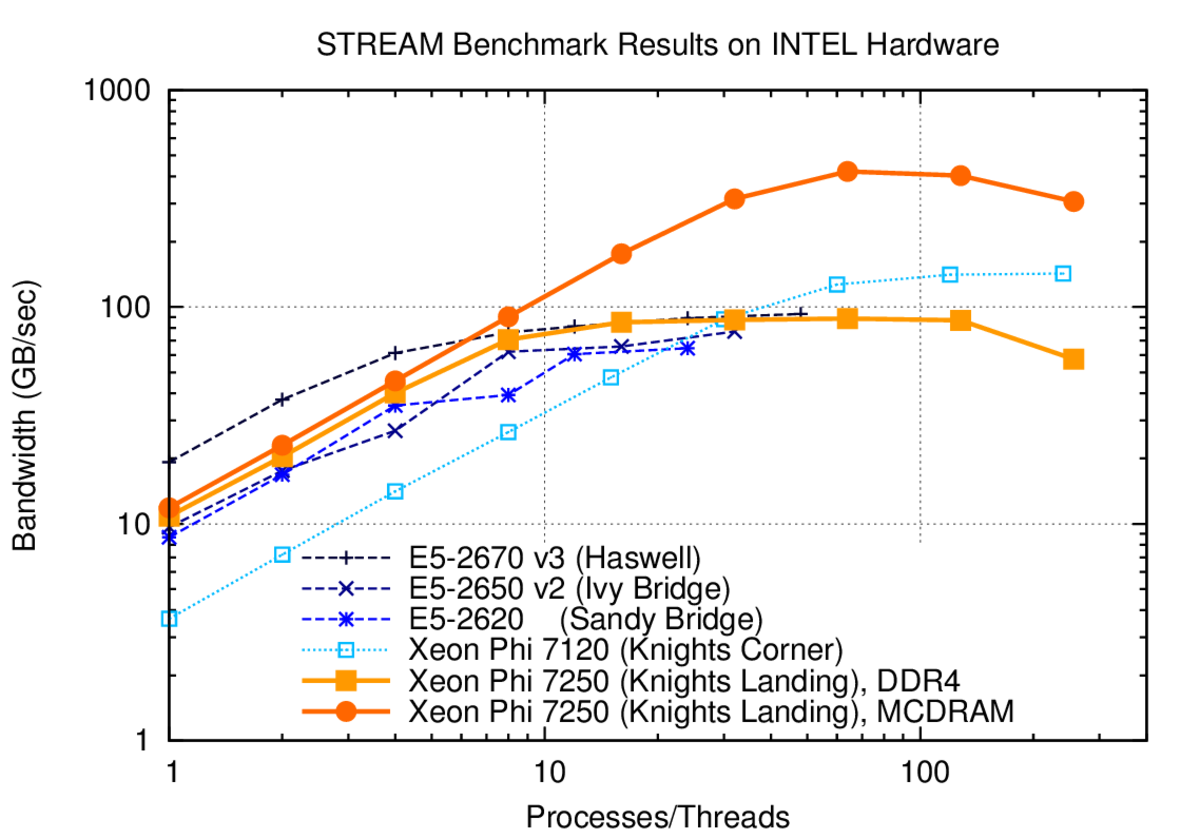
STREAM triad benchmark results for Knights Landing in comparison to three Intel Xeon generations (dual socket) and Knights Corner. A single KNL core achieves about the same memory bandwidth as Ivy Bridge and Sandy Bridge Xeons for small thread counts. Peak bandwidth is obtained with one thread per core; oversubscription reduces memory bandwidth slightly.
MCDRAM memory bandwidth scales beyond 400 GB/sec, which is comparable to the practical memory bandwidth offered by recent GPUs. However, high bandwidth *requires* high thread/process counts: At least 16 cores need to be busy to surpass the 100 GB/sec mark. DDR4 bandwidth saturates at 90 GB/sec, similar to Haswell Xeons. An interesting observation is that bandwidth slightly degrades if four threads are active per core: 256 threads achieve 57 GB/sec with DDR4 and 306 GB/sec with MCDRAM, while 64 threads achieve 88 GB/sec (DDR4) and 421 GB/sec (MCDRAM).
Conclusions
KNL is a major step forward compared to KNC. At the same time, the difference between Xeons and Xeon Phis are now much smaller than they used to be: A dual-socket Broadwell Xeon system provides up to 48 physical cores, which is not too far from the 64/68/72 cores offered by Knights Landing. MCDRAM is the major reason why one may go for Xeon Phi. On the other hand, I suspect that it is only a matter of time until we see integrated RAM on Xeons.
Overall, the KNL STREAM benchmark results are very promising. Nonetheless, I still need to explore the performance of KNL for sparse matrix-vector products as well as sparse matrix-matrix products to get a more complete picture about the suitability of KNL for the numerical solution of partial differential equations. More to come...
Resources
- Benchmark code repository
- Former blog post on STREAM results for KNC, Haswell, Ivy Bridge, and Sandy Bridge
This blog post is for calendar week 15 of my weekly blogging series for 2016.